2024. 6. 26. 13:25ㆍinformation/AI

초기의 인공지능 연구는 주로 한정된 규칙으로 이루어진 환경에서 성공을 거두었습니다.

컴퓨터는 0,1로 이루어져 있고 어마무시한 속도로 빠르게 계산하죠.
그렇기 때문에 규칙이 정해진 체스, 단순계산은 컴퓨터를 따라갈 수 없습니다.

그렇다 사람이 하는 일상적인 활동들을 컴퓨터가 할 수는 없을까?라는 물음에서부터 시작된 것이 바로 지식베이스를 기반한 접근 방식입니다. 하지만, 지식베이스에 모든 경우의 수를 넣기도 힘들뿐더러 확장한다고 하지만 항상 예외가 발생하고 오류가 발생했습니다.

그렇다면 사람이 모든 규칙을 추가하기에는 한계가 있기 때문에 컴퓨터가 스스로 규칙을 학습하게 하는 기술은 없을까?라는 물음에서 시작된 것이 바로 머신러닝(기계학습)입니다.

예를 들어, 많은 데이터를 제공하고 어떤 특징을 가진 데이터가 정답인지 아닌지를 알려주고 스스로 방법을 찾도록 하는 것이머신러닝입니다. 쉽게 이야기해서, 입력을 받아서 출력하는 함수 y=f(x)를 학습한다고 생각하면 됩니다.
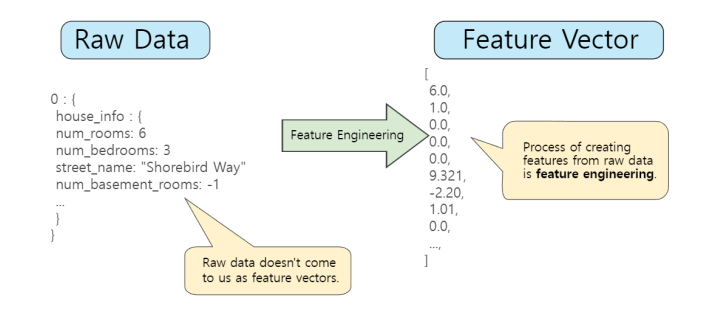
머신러닝은 어떠한 특징을 가진 데이터들로부터 학습을 하는데 어떠한 특징들을 컴퓨터가 이해할 수 있도록 바꿔야합니다. 이러한 데이터 형태를 특징점(feature)라고 하며 보통 숫자로 이루어져 있습니다. 같은 데이터를 써도 어떤 특징점으로 바꾸어서 머신러닝을 수행하는지에 따라서 엄청난 성능 차이가 발생하게 됩니다.


머신러닝이 작동하는 원리를 살펴보면 위와 같습니다. 고양이가 가지는 특징점을 바탕으로 결과값을 도출하게 되는 것이죠.

머신러닝 작업의 종류에는 크게 3가지가 있습니다. 지도학습, 비지도학습, 강화학습으로 나뉘며 지도학습은 정답(레이블)을 알려주고 학습시키는 방법입니다. 지도학습도 회귀와 분류로 나뉩니다. 회귀는 입력값인 x와 출력값인 y가 주어질때 매핑 함수를 학습하는 것을 regression 회귀라고 합니다. 분류는 y가 이산적인 경우, 입력을 2개 이상의 클래스로 나누는 것을 말합니다.

비지도 학습은 정답(레이블)이 주어지지 않고 입력값만 주어집니다. 가장 대표적인 비지도 학습으로는 클러스터링(군집화)가 있습니다. 군집화는 데이터 간의 거리를 계산하여 입력을 몇 개의 그룹으로 나누는 것을 말합니다.
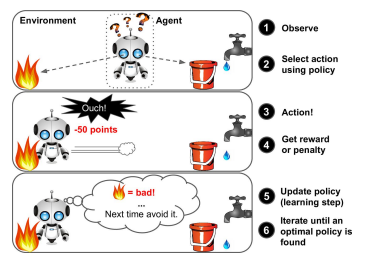
강화학습은 데이터가 주어지는 것이 아닙니다. 모델이 직접 행동하면 각각의 행동에 대해 잘했는지 못했는지 피드백을 받으며 학습하는 방식을 말합니다. 알파고가 바로 강화 학습의 대표적인 예입니다.
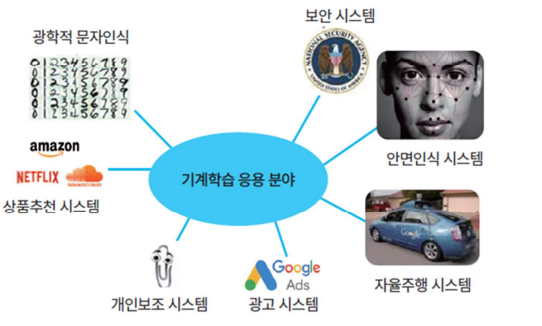
기계학습(머신러닝)은 주로 경우의 수가 많아서 프로그래밍하는 것이 어려운 경우에 주로 사용됩니다. 보안시스템, 안면인식 시스템, 자율주행시스템, 광고시스템, 상품추천 시스템 등에 사용됩니다.
'information > AI' 카테고리의 다른 글
| [딥러닝] (0) | 2024.06.26 |
|---|---|
| [유전자 알고리즘] (0) | 2024.06.20 |
| [퍼지논리] (0) | 2024.06.20 |
| [전문가 시스템] (0) | 2024.06.20 |